아래의 게시글을 참고하여 수행하고 번역 후 요약해 보았다.
https://github.com/AlexeyAB/darknet#how-to-train-to-detect-your-custom-objects
GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Da
YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object Detection (Windows and Linux version of Darknet ) - GitHub - AlexeyAB/darknet: YOLOv4 / Scaled-YOLOv4 / YOLO - Neural Networks for Object ...
github.com
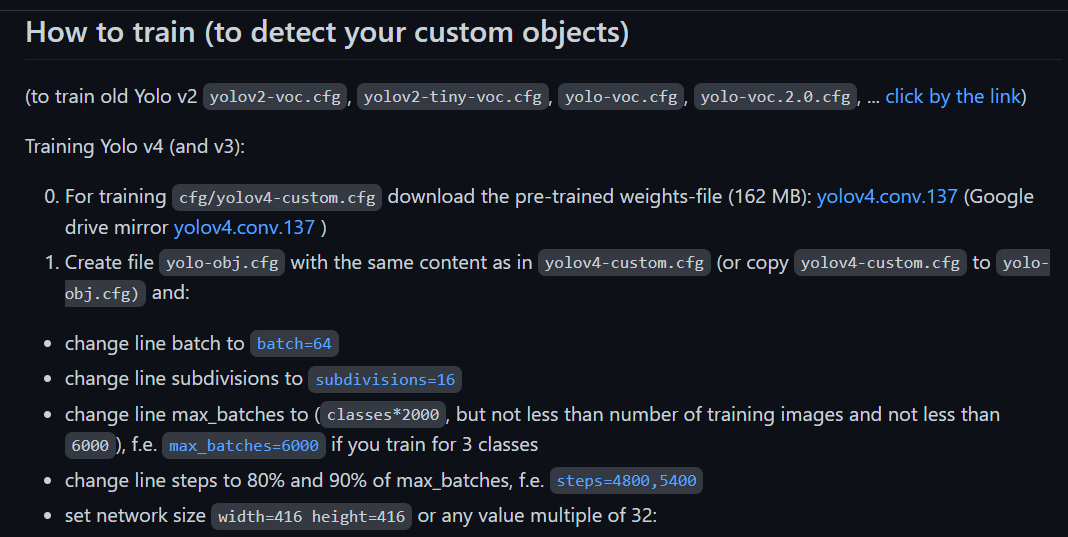
학습방법
1. 미리 학습된 가중치 yolov4.conv.137 파일(162 MB)을 다운 받는다.
2. yolov4-custom.cfg 파일을 복사하여 yolo-obj.cfg 파일을 생성한 후, 아래의 내용을 변경한다.
아래의 예시는 분류해야할 classes=3인 경우이다.
- batch=64
- subdivisions=16
- max_batches=6000 분류해야하 할 객체(object) 1개당 2000을 곱하면 된다.
- steps=4800,5400 max_batches의 80%, 90%의 값으로 설정한다.
- network size는 width=416 height=416으로 설정하거나 32배수로 설정한다.
: darknet/cfg/yolov3.cfg 파일의 경우, 8행 라인에 있다.
- classes=3 분류해야할 객체(object)의 수를 설정한다.
: darknet/cfg/yolov3.cfg 파일의 경우, 610, 696, 783행 라인에 있다. - filters=24 filters의 값은 ( classes + 5 ) * 3의 값으로설정한다.
: darknet/cfg/yolov3.cfg 파일의 경우, 603, 689, 776행 라인에 있다. - [Gaussian_yolo] 레이어를 사용할 경우, filters=36 filters의 값은 ( classes + 5 ) * 3의 값으로설정한다.
darknet/cfg/Gaussian_yolov3_BDD.cfg 파일의 경우, 604, 696, 789 행 라인에 있다.
3. "build\darknet\x64\data\" 경로의 obj.names에 분류할 객체의 이름을 설정한다.
person
bicycle
car
4."build\darknet\x64\data\" 경로의 obj.data에 분류할 객체의 수를 설정한다.
classes = 3
train = data/train.txt
valid = data/test.txt
names = data/obj.names
backup = backup/
5. 인식할 이미지 파일은 "build\darknet\x64\data\obj\" 경로에 저장한다.
6. 학습할 이미지의 datasets은 YOLO MARK를 이용하여 생성할 수 있다.
Yolo v2 & v3: https://github.com/AlexeyAB/Yolo_mark
GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2
GUI for marking bounded boxes of objects in images for training neural network Yolo v3 and v2 - GitHub - AlexeyAB/Yolo_mark: GUI for marking bounded boxes of objects in images for training neural n...
github.com
YOLO MARK를 이용하여 이미지의 인식할 객체를 bounding box로 지정하면 아래의 형식으로 저장된다.
<object-class> <x_center> <y_center> <width> <height>※ 주의: bounding box의 <x_center> <y_center> 좌표는 중심 좌표이다. (왼쪽 상단의 좌표가 아님)
1 0.716797 0.395833 0.216406 0.147222
0 0.687109 0.379167 0.255469 0.158333
1 0.420312 0.395833 0.140625 0.166667
7. convolutional layers로 미리 학습된 파일을 다운 받은 후, "build\darknet\x64" 경로에 저장한다.
- for yolov4.cfg, yolov4-custom.cfg (162 MB): yolov4.conv.137 (Google drive mirror yolov4.conv.137 )
- for yolov4-tiny.cfg, yolov4-tiny-3l.cfg, yolov4-tiny-custom.cfg (19 MB): yolov4-tiny.conv.29
- for csresnext50-panet-spp.cfg (133 MB): csresnext50-panet-spp.conv.112
- for yolov3.cfg, yolov3-spp.cfg (154 MB): darknet53.conv.74
- for yolov3-tiny-prn.cfg , yolov3-tiny.cfg (6 MB): yolov3-tiny.conv.11
- for enet-coco.cfg (EfficientNetB0-Yolov3) (14 MB): enetb0-coco.conv.132
8. 아래의 cmd 명령어를 이용하여 학습을 시작한다.
- : (Windows) darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137
- : (Linux) ./darknet detector train data/obj.data yolo-obj.cfg yolov4.conv.137
끝.
'인공지능 > 이미지 인식' 카테고리의 다른 글
| Error: cuDNN isn't found FWD algo for convolution. 해결 방법 (0) | 2022.01.28 |
|---|---|
| AlexeyAB/darknet Yolo v4, v3 and v2 for Windows - 이미지 인식 (0) | 2022.01.23 |
| AlexeyAB/darknet Yolo v4, v3 and v2 for Windows - 개발 환경 (0) | 2022.01.23 |

